面试题 - 前端 - JS
介绍 JS 有哪些内置对象?
- 数据封装类对象(可以 new 的):Object、Array、Boolean、Number、String
- 其他对象:Function、Arguments、Math、Date、RegExp、Error
- ES6 新增对象:Symbol(标识唯一性的 ID)、Map、Set、Promises、Proxy、Reflect
如何最小化重绘(repaint)和回流(reflow)?
- 需要要对元素进行复杂的操作时,可以先隐藏(display:”none”),操作完成后再显示
- 需要创建多个 DOM 节点时,使用 document.createDocumentFragment 创建完后一次性的加入 document
- 缓存 Layout 属性值,如:var left = elem.offsetLeft; 这样,多次使用 left 只产生一次回流
- 尽量避免用 table 布局(table 元素一旦触发回流就会导致 table 里所有的其它元素回流)
Javascript 作用域链?
- 全局函数无法查看局部函数的内部细节,但局部函数可以查看其上层的函数细节,直至全局细节
- 如果当前作用域没有找到属性或方法,会向上层作用域[[Scoped]]查找,直至全局函数,这种形式就是作用域链
例如一个函数需要使用一个属性,如果在当前函数作用域找不到这个属性,则会到更上一级的函数作用域去找,直至全局函数。这种形式就是作用域链。
数据请求
方法一:fetch
1 | fetch('url', { method: 'post', body: '', credencial: 'include' }) |
方法二:XHR
1 | var xhr = new XMLHttpRequest(); |
方法三:jsonp
jsonp 的原理是 用 script 标签应用 JS 文件不受跨域限制。
所以前端动态创建 script 标签指向服务端接口。
服务端返回的数据格式是test('["111","222","3333"]');。
前端定义好test这个方法接收数据。
jsonp 只能做 get 请求,不可以中断。
跨域和同源策略
所谓的同源策略其实是浏览器的一种机制,只允许在同源,也就是同协议、同域名、同端口的的情况下才能进行数据交互。 但是我们在开发项目的过程中, 往往一个项目的接口不止一个域,所以往往就需要做跨域的处理,通常的跨域方式有这么几种:
方法一:jsonp
方法二:CORS,依赖服务端对前端的请求头信息进行放行,不做限制。
1 | Access-Control-Allow-Origin配置成* |
方法三:前端在开发阶段,可以使用代理服务器去访问目标服务器。
面向对象
(1)构造函数
1 | function Test(name, age) { |
人话:在一个函数内部,写好了 this 挂上属性。外面再 new 这个函数,就可以创建出实例对象出来。
(2)原型
1 | //内存只有一份 |
人话:原型的目的是共享内存。
每个对象的属性和方法在内存中都是独立的。如果某些属性或方法不需要各个对象内存独立,则可以使用原型。使用原型就可以使同一个构造函数创建出来的所有对象有共同的属性或方法。例如所有的数组都有 concat 方法。
原型容易被覆盖,例如 vue 中覆盖了数组原型中的操作方法(例如 push,pop,splice),使得数组调用这些方法后,有响应式效果。
(3)继承
1 | //构造函数继承 |
人话:有两种继承方式:
方法一:构造函数继承。在子构造函数中使用 call 或者 apply,把父构造函数的属性都继承过来。这个方法的缺点是无法继承父构造函数的原型。
方法二:原型继承。子构造函数的原型覆盖为父构造函数的原型。
(4)原型链
原型链的基本原理:任何一个实例,通过原型链,找到它上面的原型,该原型对象中的方法和属性,可以被所有的原型实例共享。
人话:如果一个对象
obj访问一个属性a,会先找对象本身有没有属性a。如果没有,就会通过obj.__proto__找到创建obj的构造函数的prototype,在这上面找属性a。如果还没有找到,就继续沿着上一级继续找,直到找到原型的顶点Object。如果在没有找到就报错了。
闭包
函数内部返回另一个函数。另一个函数被外界引用。垃圾回收机制无法回收。这就是 js 的一个特性:闭包。
目的:实现数据持久化,并私有,但会有内存泄露风险。例如做一个计数函数,调用一次,计数器++。
计数器实例:
1 | const fn = () => { |
实际应用:模块化,防抖,截流。
模块化实例:
1 | const MyModule = () => { |
防抖实例:(先延迟,后执行,例如文本框输入,自动搜索)
1 | function debounce(fn, wait) { |
截流实例:(先执行,后延迟,例如点击按钮)
1 | function throttle(fn, wait) { |
数组去重
方法一:利用 Set 去重
1 | var arr = [1, 2, 3, 4, 3, 4]; |
方法二:利用 for 嵌套 for,然后 splice 去重
1 | function unique(arr) { |
数组合并
- concat
- […a, …b]展开运算符
- [a, b].flat()
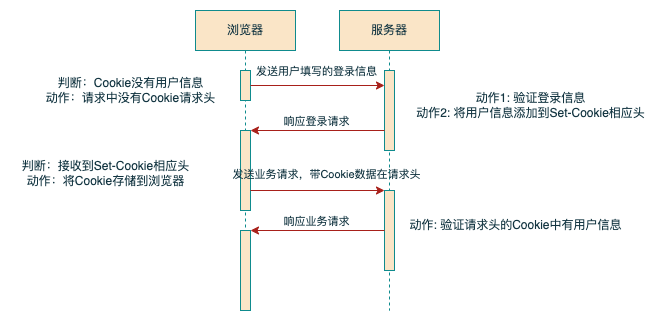
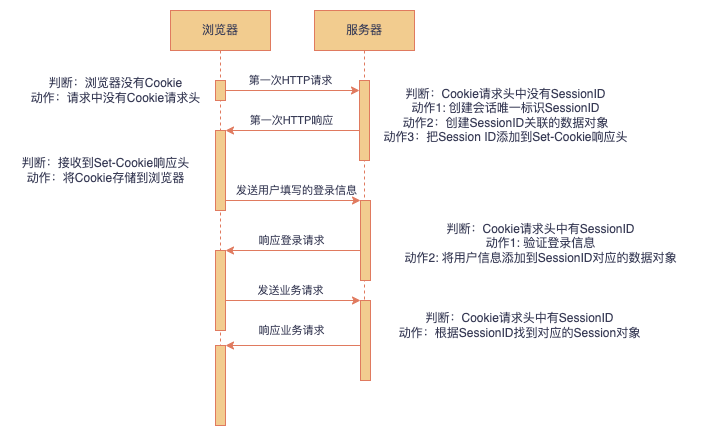
cookie 和 session (登录鉴权是怎么做的)
传统的 cookie 验证(有 Cookie 被盗用风险):
session 验证:
线程和进程的区别
进程是资源分配的最小单元,线程是代码执行的最小单元。
一个应用程序可能会开启多个进程,进程之间数据不共享,一个进程内部可以开启多个线程,线程之间的数据可以共享的,所以多线程的情况下,往往要考虑的是线程间的执行顺序问题。
浏览器其实也可以通过 webWorkers 开启多线程。
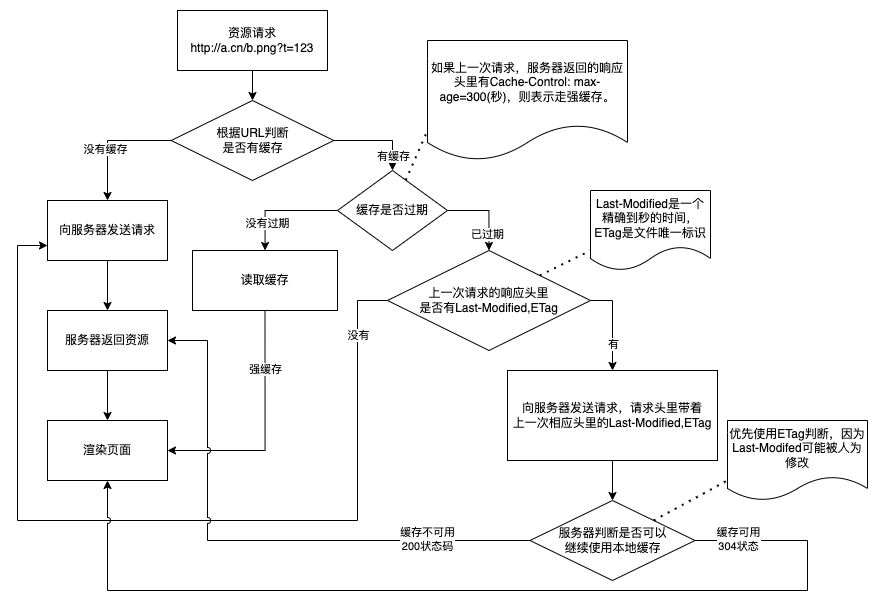
协商缓存和强缓存区别
强缓存不走服务器,协商缓存服务器返回 304 状态码。
http 和 https
HTTP 是明文传输,数据容易被网络中间节点偷窥或篡改。例如有些网络提供商会在用户浏览的网页中输入广告,就是篡改了网页文件。
HTTP 使用 80 端口。
HTTPS 是加密传输。流程如下:
- 客户端向服务端发送握手信息;
- 服务端会将 SSL 证书(包含加密公钥,签发的 CA 机构)发送给客户端;
- 客户端检查签发的 CA 机构是否值得信任。如果检查通过就用证书中的加密公钥加密要传输的数据(该数据无法用公钥解密,应为非对称加密)给服务端。
- 服务端拿到客户端的加密数据后,用与公钥配对的私钥解密。
HTTPS 使用 443 端口。
HTTPS 也不一定安全。SSL 证书是由 CA 机构审核签发的,如果 CA 机构没有做好审核,就把 SSL 证书签发给了坏家伙,那 HTTPS 也不安全了。
对于工作中的跨域问题你是怎么解决的
在本地开发的过程中,本地服务器访问测试服务器接口的,也基本都是后端去处理 CORS 跨域,但是有些时候也可能需要前端在脚手架对应的 devServer 中配置 Proxy 来进行开发时候的跨域处理。
在线上的各种环境中(开发、测试、生产)环境一般是不会有跨域问题的,因为服务器和前端资源一般是会部署在同一个域的服务器下的,但是也有端口或者不同域的情况,这些时候往往都是后端去利用 CORS 来处理的跨域问题。
在一些极少的情况下加,项目中可能会访问一些第三方的 Api,比如定位、天气等等接口的时候,可能会根据接口需求进行 jsonp 的跨域处理。
事件循环
同步代码(同步任务):立即放到JS 引擎(JS 主线程)执行,并原地等待结果。
异步代码(异步任务):先放入宿主环境(浏览器/Node),不必原地等待结果,并不阻塞主线程继续往下执行,异步结果在将来执行。
异步代码有:
- 定时器
- Ajax 请求
- UI 事件
- Promise 的 then(Promise 本身是同步的)
总结:
- JS 是单线程,为防止代码阻塞,把代码(任务)分成:同步和异步。
- 同步代码给 JS 引擎执行,异步代码交给宿主环境。
- 同步代码放入执行栈中,异步代码等待时机成熟送入任务队列排队。
- 执行栈执行完毕,会去任务队列看是否有异步任务,有就送到执行栈执行。反复循环查看执行,这个过程就是事件循环。
微任务和宏任务
JS 把异步任务分为宏任务和微任务。
宏任务是由宿主(浏览器、Node)发起:script 全部代码、setTimeout、setInterval、网络请求(Ajax/Fetch)、事件。
微任务是由 JS 引擎发起:Promise、Process.nextTick(Node 独有)。
Promise 本身同步,then/catch 的回调函数时异步的。
总结:
- 同步代码放到执行栈中;微任务的回调函数在时机成熟时,放到微任务队列中;宏任务的回调函数在时机成熟时,放到宏任务队列中。
- 执行在执行栈中的同步代码。
- 到微任务队列中找微任务,放到执行栈中执行。直至微任务队列中没有微任务。
- 到宏任务队列中找宏任务,放到执行栈中执行。直至宏任务队列中没有宏任务。
http 状态码有那些?分别代表是什么意思?
100 Continue 继续,一般在发送 post 请求时,已发送了 http header 之后服务端将返回此信息,表示确认,之后发送具体参数信息
200 OK 正常返回信息
201 Created 请求成功并且服务器创建了新的资源
202 Accepted 服务器已接受请求,但尚未处理
301 Moved Permanently 请求的网页已永久移动到新位置。
302 Found 临时性重定向。
307 Internal Redirect 内部重定向
304 Not Modified 自从上次请求后,请求的网页未修改过。 协商缓存
200 memory cache 强缓存
400 Bad Request 服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求。
401 Unauthorized 请求未授权。
403 Forbidden 禁止访问。
404 Not Found 找不到如何与 URI 相匹配的资源。
500 Internal Server Error 最常见的服务器端错误。
503 Service Unavailable 服务器端暂时无法处理请求(可能是过载或维护)。
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
- 浏览器查找域名对应的 IP 地址(DNS 查询:浏览器缓存->系统缓存->路由器缓存->ISP DNS 缓存->根域名服务器)
- 浏览器向 Web 服务器发送一个 HTTP 请求(TCP 三次握手),如果是 HTTPS,多 9 次握手。
- 服务器 301 重定向(从 http://example.com 重定向到 http://www.example.com)
- 浏览器跟踪重定向地址,请求另一个带 www 的网址
- 服务器处理请求(通过路由读取资源)
- 服务器返回一个 HTTP 响应(报头中把 Content-type 设置为 ‘text/html’)
- 浏览器进 DOM 树构建
- 浏览器发送请求获取嵌在 HTML 中的资源(如图片、音频、视频、CSS、JS 等)
- 浏览器显示完成页面
- 浏览器发送异步请求
前端攻击
一、CSRF(Cross-site request forgery):跨站请求伪造。
攻击者盗用普通用户的身份,以该用户的名义,向服务端发送恶意的请求。(例如以该用户的身份发帖,点赞,甚至银行交易)
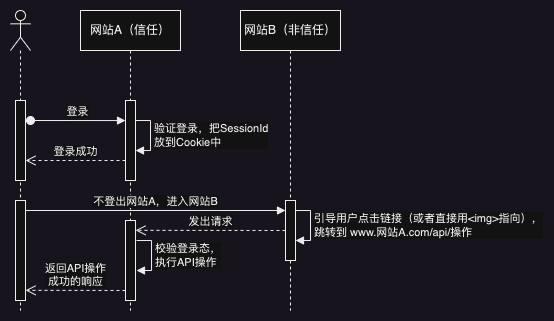
防御方法:
- 尽量使用 POST 请求。
- 加入验证码。
- 验证 Referer。(Referer 是请求方域名)
- 推荐:验证 token。客户端先问服务端要一个 token(服务端也会缓存这个 token),提交请求的时候连这个 token 一起给服务端。服务端接收到请求,验证 token 是否是自己生成的。如果是,则执行请求,并销毁当前 token,并给客户端一个新的 token.
二、XSS(Cross-site scripting)跨站脚本攻击
攻击者通过各种办法,在网站的页面上插入自己的脚本。普通用户访问该网站页面的时候,执行攻击者的脚本。(攻击者的脚本可以是把普通用户的 Cookie 发送到攻击者的网站)
防御方法:
- 服务端对接口请求参数做过滤。
- 客户端对接口响应结果做 HTML 转义。